


合成數據的質量主要取決於生成這些數據的模型質量,以及原始數據的代表性和質量。對於後者,這是每個數據分析師都熟知的問題,因此不需要進一步評論;但對於模型質量的問題,我們值得花更多的時間來探討。
圖1. 考慮數據質量評估的合成數據生成過程。
這裡我們不僅指的是模型(算法)本身,而是整個過程,這個過程能幫助我們生成高質量的合成數據。獲取這些數據需要額外的驗證步驟,例如將模型的結果與現實世界的數據(原始數據)進行全面比較。這樣的過程的示例步驟在圖1中以示意圖的形式展示,並在圖2中以實際實施的流程圖(flow)形式展示於SAS Viya平台的SAS Studio工具中。
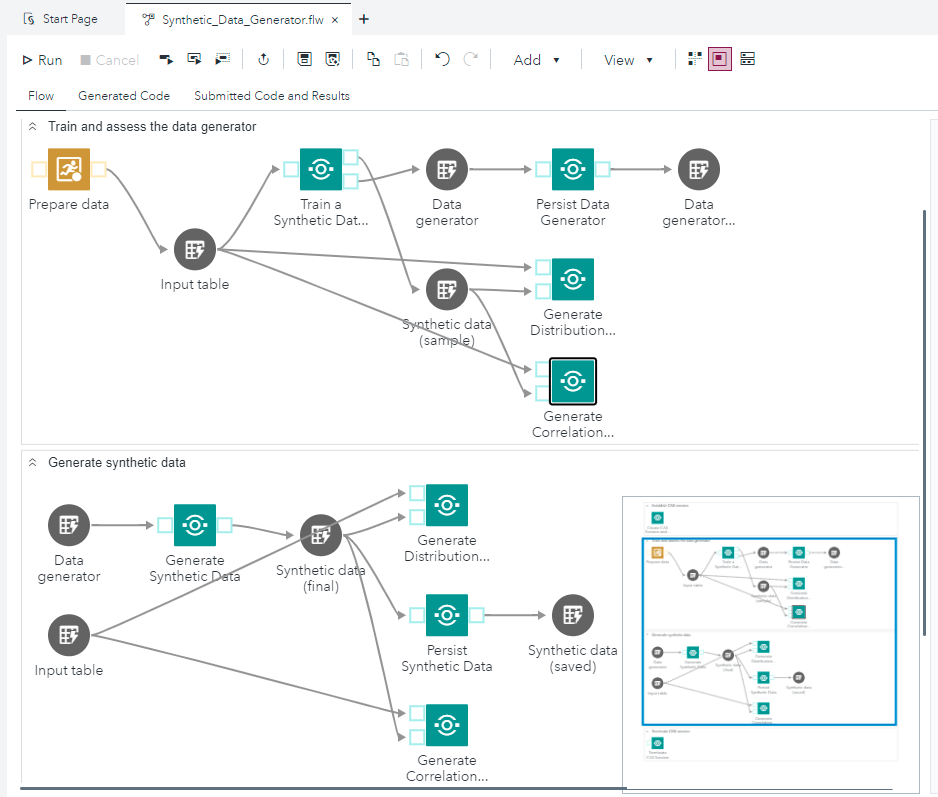
圖2. 在SAS Viya平台上使用SAS在Github上提供的現成節點實施GAN生成器的示例。
SMOTE模型
在生成合成數據的方法中,目前最受歡迎的有兩種技術,這兩種技術基於不同的假設,適用於解決在現實(原始)數據中識別的特定問題。第一種是SMOTE(合成少數類過採樣技術),由Nitesh V. Chawla等人在2002年提出,這是一種主要用於解決不平衡數據集的過採樣方法。這種方法的想法很簡單:隨機選取一個樣本及其k個來自同一類別(組別、層次)的最近鄰,然後通過在選定樣本和其鄰居之間進行插值來生成合成觀察值。這樣我們就能獲得與原始數據相似的觀察值,雖然在細節上有所不同。這種方法的理論在圖3中進行了展示。

圖3. SMOTE方法的概念。
GAN網絡
第二種方法,具有更廣泛的應用潛力,利用了GAN(生成對抗網絡)。在這種情況下,我們充分利用生成的人工智慧來創造合成數據(這些數據特別可以用來……訓練生成性人工智慧模型)。這種方法由Ian Goodfellow等人在2014年提出,因此比SMOTE技術年輕幾年。最初,它在圖像處理方面取得了很大成功(包括生成現實的轉換、填充等),但隨著時間的推移,某些修改開始被用於生成標準的表格形式的合成數據。
特別是CPCTGAN(保持相關性的條件表格GAN)模型是為了最好地克服處理表格數據時的典型問題而創建的,例如需要同時建模離散和連續變量、每個連續變量中的多模態非高斯值,或重要的分類變量不平衡等,同時保持數據質量的基本標準,即反映原始數據集中變量對之間的相關係數(線性)。在這種方法中,數據質量的評估(圖1中的步驟6和8)主要涉及對變量之間的分佈和相關性的分析。實踐表明,這種方法能夠生成在這些標準下幾乎無法區分的合成數據,與真實數據相似。
學習過程
如果不考慮上述細節(這些細節是對表格數據挑戰的回應),基於GAN網絡的模型的基本概念是有趣的,因為它可以用博弈論的語言來表達,將其過程簡化為兩個玩家——生成器和判別器之間的競爭,直到達到平衡。生成器和判別器是兩個神經網絡,在這場比賽中扮演著不同但互補的角色。生成器根據輸入的噪聲(來自選定的先驗分佈的隨機數據,通常是高斯噪聲)生成合成數據,並且從未“看到”真實數據。它的任務(最終目標)是生成具有真實數據(原始數據)特徵的合成數據。另一方面,判別器在真實數據和合成數據(來自生成器)上進行訓練,估計輸入數據是真實的還是合成的(不真實的)概率,最終目的是拒絕合成數據(即在統計意義上進行區分)。因此,它實際上是一個sigmoid,給出類似於邏輯回歸的答案,邏輯回歸也用於構建評分卡(這也是一種分類器/判別器,學習區分兩個人群,例如在銀行或客戶“好”與“壞”的市場營銷中)。生成器的訓練基於判別器的錯誤,而整個遊戲的目標是達到鞍點(生成器和判別器之間的平衡狀態)在最小化最大化的遊戲中。整個過程的運作方式在圖4中以示意圖的形式展示。
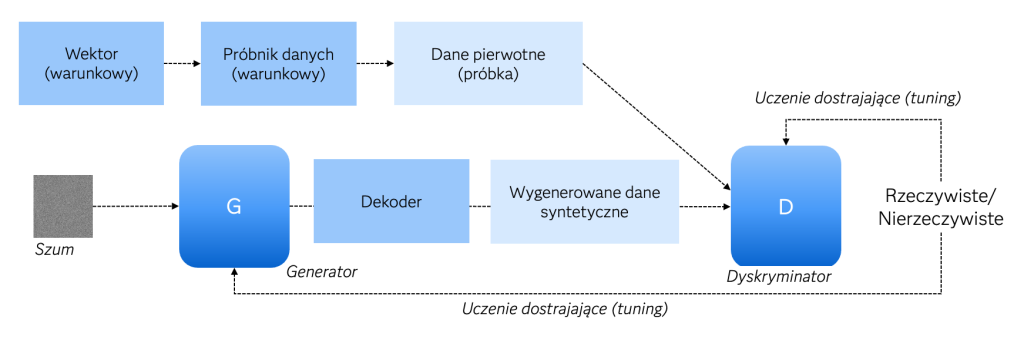
圖4. 基於GAN網絡的合成數據生成器的運作示意圖。
無編碼的合成數據
SMOTE和CPCTGAN模型可在SAS Viya平台上使用。為了方便實際應用,SAS公司準備了可在SAS Studio工具中使用的現成節點,SAS Viya平台的用戶可以使用這些節點構建自己的低代碼/無代碼數據流。這些節點及其隨附的說明可在Github上獲得:
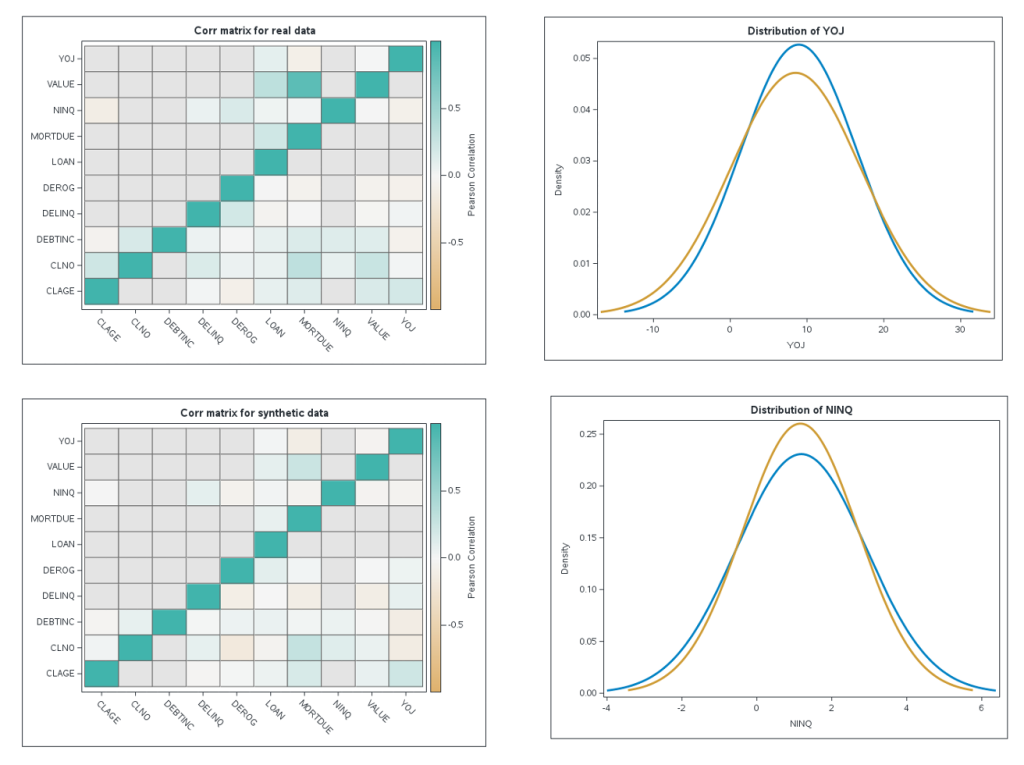
圖5. 基於GAN網絡的方法的示例輸出數據集。
[1] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). 生成對抗網絡。神經信息處理系統的進展,27。
[2] Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P. (2002). “SMOTE:合成少數類過採樣技術。”人工智慧研究期刊 16:321–357
本文由 AI 台灣 運用 AI 技術編撰,內容僅供參考,請自行核實相關資訊。
歡迎加入我們的 AI TAIWAN 台灣人工智慧中心 FB 社團,
隨時掌握最新 AI 動態與實用資訊!








{kind=link}