


LG AI 研究所最近發布了基於 EXAONE 3.5 的雙語模型,專精於英語和韓語,並將其開源,這是繼其前身 EXAONE 3.0 成功後的又一進展。研究團隊擴展了 EXAONE 3.5 模型,包含三種類型,針對特定使用情境設計:
2.4B 模型是一個超輕量版本,優化用於設備端使用。它可以在低規格的 GPU 上運行,並適用於基礎設施有限的環境。
輕量級的 7.8B 模型在性能上優於其前身 EXAONE-3.0-7.8B-Instruct 模型,同時保持通用性,適合多種用途。
32B 模型則代表了高性能的前沿選擇,適合需要計算能力的用戶。
EXAONE 3.5 模型展現了卓越的性能和成本效益,這得益於 LG AI 研究所的創新研發方法。EXAONE 3.5 的一大特點是支持長上下文處理,能夠處理多達 32,768 個標記。這一能力使其能夠有效應對現實使用情境和增強檢索生成 (RAG) 的需求,因為這些情境中常常需要處理較長的文本輸入。EXAONE 3.5 系列中的每個模型在需要長上下文理解的現實應用和任務中都展現了最先進的性能。
EXAONE 3.5 的訓練方法和架構創新
訓練 EXAONE 3.5 語言模型涉及先進配置、預訓練策略和後訓練調整的結合,以最大化性能和可用性。這些模型基於最先進的僅解碼器 Transformer 架構,根據模型大小的不同而有所變化。雖然在結構上與 EXAONE 3.0 7.8B 相似,但 EXAONE 3.5 模型引入了改進,例如延長的上下文長度,支持多達 32,768 個標記,這比之前的 4,096 個標記有了顯著增長。該架構還包含了先進的特性,如 SwiGLU 非線性、分組查詢注意力 (GQA) 和旋轉位置嵌入 (RoPE),確保高效處理並增強對英語和韓語的雙語支持。所有模型共享 102,400 個標記的詞彙,兩種語言均分。
EXAONE 3.5 的預訓練階段分為兩個階段進行。第一階段專注於多樣化數據來源,以提升一般領域的性能,而第二階段則針對需要改進能力的特定領域,如長上下文理解。在第二階段,使用了基於重播的方法來解決災難性遺忘,使模型能夠保留初始訓練階段的知識。在預訓練過程中優化了計算資源;例如,32B 模型在計算需求顯著低於其他同類型模型的情況下實現了高性能。還進行了嚴格的去污染過程,以消除訓練數據中的污染範例,確保基準評估的可靠性。
後訓練階段,模型經過監督微調 (SFT),以增強其有效響應各種指令的能力。這涉及從網絡語料庫中衍生的知識分類法創建指令-響應數據集。該數據集設計包括各種複雜性,使模型能夠在各種任務中良好地進行概括。然後,使用直接偏好優化 (DPO) 和其他算法進行偏好優化,以使模型與人類偏好對齊。這一過程包括多個訓練階段,以防止過度優化並改善輸出與用戶期望的對齊。LG AI 研究所進行了廣泛的審查,以解決潛在的法律風險,如版權侵權和個人信息保護,以確保數據合規。採取措施去識別敏感數據,確保所有數據集符合嚴格的倫理和法律標準。
基準評估:EXAONE 3.5 雙語模型的無與倫比的性能
EXAONE 3.5 模型的評估基準分為三組:現實世界使用情境、長上下文處理和一般領域任務。現實世界基準評估模型在實際情境中理解和響應用戶查詢的能力。長上下文基準評估模型從擴展文本輸入中檢索和處理信息的能力,這對於 RAG 應用至關重要。一般領域基準測試模型在數學、編程和知識性任務中的熟練程度。EXAONE 3.5 模型在所有基準類別中表現一致良好。32B 和 7.8B 模型在現實世界使用情境和長上下文場景中表現出色,經常超越同類型的基準模型。例如,32B 模型在現實世界使用情境中平均得分 74.3,顯著超越了競爭對手如 Qwen 2.5 32B 和 Gemma 2 27B。
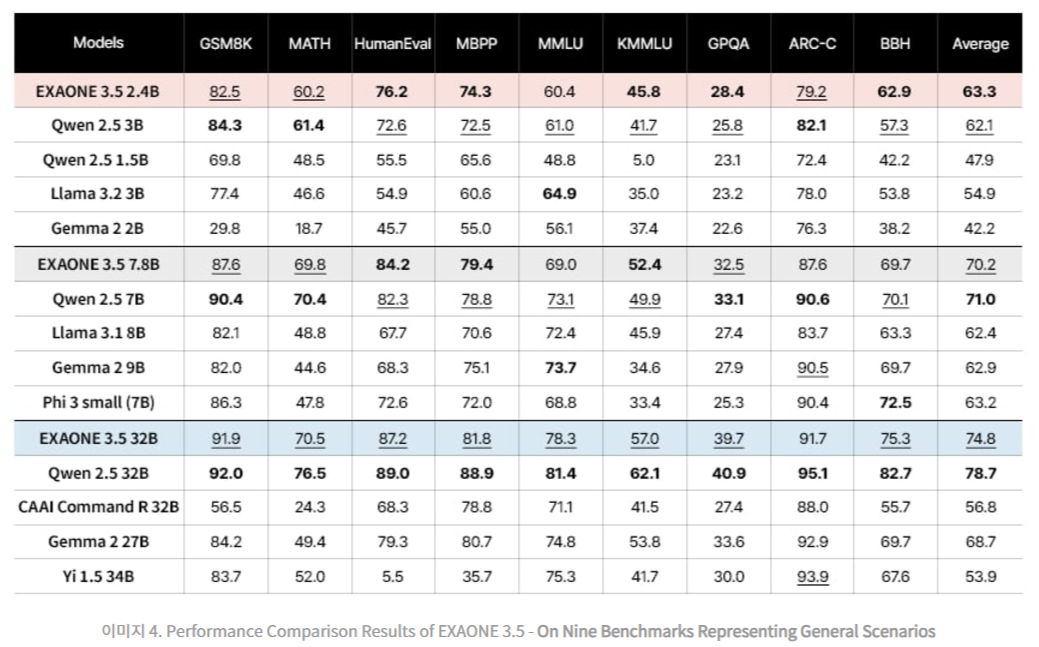
同樣,在長上下文基準中,這些模型展示了在英語和韓語中處理和理解擴展上下文的卓越能力。在 Needle-in-a-Haystack (NIAH) 測試中,所有三個模型都達到了近乎完美的檢索準確率,展示了它們在需要詳細上下文理解的任務中的強大性能。2.4B 模型是資源受限環境中的高效選擇,在所有類別中超越了同類型的基準模型。儘管其體積較小,但在一般領域任務中,如解決數學問題和編寫源代碼,仍然交出了競爭力的結果。例如,2.4B 模型在九個基準中平均得分 63.3,在多個指標上超越了較大的模型如 Gemma 2 9B。現實世界使用情境評估包括 MT-Bench、KoMT-Bench 和 LogicKor 等基準,在這些基準中,EXAONE 3.5 模型在多輪響應中獲得了高分,顯示出其雙語能力。例如,32B 模型在 MT-Bench 中獲得了 8.51 的頂級結果,生成準確且與上下文相關的響應。
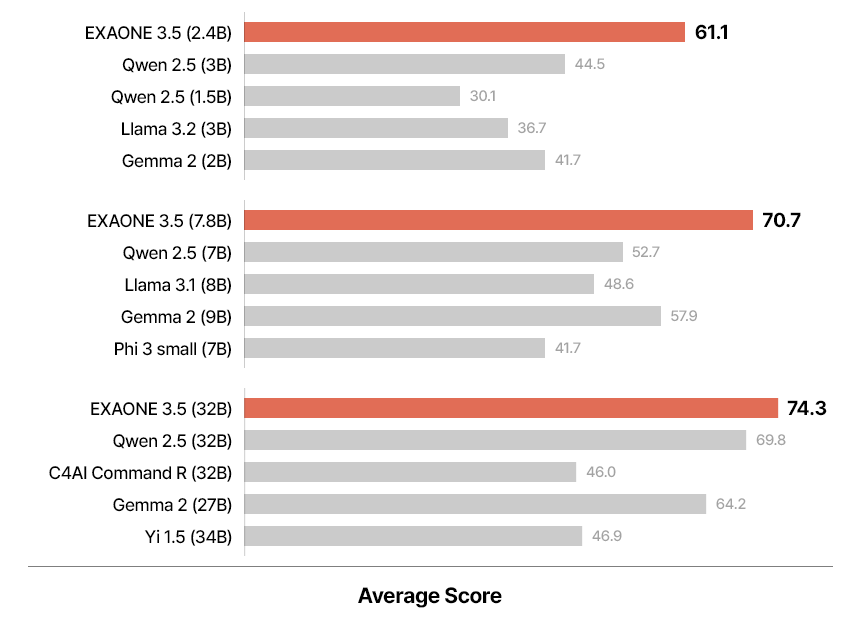
在長上下文類別中,EXAONE 3.5 模型使用 LongBench 和 LongRAG 等基準進行評估,並在內部測試中使用 Ko-WebRAG。這些模型展示了卓越的長上下文處理能力,在檢索和推理擴展文本方面持續超越基準。以 32B 模型為例,在長上下文基準中平均得分 71.1,鞏固了其在該領域的領導地位。一般領域評估包括數學、編程和參數知識的基準。EXAONE 3.5 模型在與同行的比較中表現出色。32B 模型在九個基準中平均得分 74.8,而 7.8B 模型得分 70.2。
負責任的 AI 開發:倫理和透明的實踐
EXAONE 3.5 模型的開發遵循了 LG AI 研究所的負責任 AI 開發框架,優先考慮數據治理、倫理考量和風險管理。考慮到這些模型的開放性及其在各個領域的廣泛使用潛力,該框架旨在最大化社會效益,同時保持公平、安全、負責任和透明。這一承諾與 LG AI 倫理原則相符,這些原則指導 AI 技術的倫理使用和部署。EXAONE 3.5 模型通過解決 EXAONE 3.0 發布後的反饋,為 AI 社區帶來了益處。
然而,像 EXAONE 3.5 這樣的開放模型的發布也帶來了潛在風險,包括不平等、誤用和意外生成有害內容。LG AI 研究所進行了 AI 倫理影響評估,以減輕這些風險,識別出偏見、隱私侵犯和法規遵從等挑戰。對所有數據集進行了法律風險評估,並通過去識別過程刪除了敏感信息。對訓練數據中的偏見進行了預處理文檔和評估,以確保數據質量和公平性。為了確保模型的安全和負責任使用,LG AI 研究所驗證了所使用的開源庫,並承諾監控不同司法管轄區的 AI 法規。還優先考慮增強 AI 推理的可解釋性,以建立用戶和利益相關者的信任。雖然完全解釋 AI 推理仍然具有挑戰性,但持續的研究旨在改善透明度和問責制。EXAONE 3.5 模型的安全性使用了由韓國科學技術部提供的第三方數據集進行評估。這一評估測試了模型過濾有害內容的能力,結果顯示出一定的有效性,但也突顯了進一步改進的必要性。
關鍵要點、現實世界應用和 EXAONE 3.5 的商業合作
卓越的長上下文理解:EXAONE 3.5 模型因其強大的長上下文處理能力而脫穎而出,這是通過 RAG 技術實現的。每個模型都能有效處理 32K 標記。與聲稱理論上長上下文能力的模型不同,EXAONE 3.5 的“有效上下文長度”為 32K,使其在實際應用中非常有效。其雙語能力確保在處理複雜的英語和韓語上下文時表現一流。
卓越的指令跟隨能力:EXAONE 3.5 在以可用性為重點的任務中表現出色,在七個代表現實世界使用情境的基準中交出了最高的平均分數。這表明其能夠提升工業應用中的生產力和效率。所有三個模型在英語和韓語中均顯著優於同類型的全球模型。
強大的一般領域性能:EXAONE 3.5 模型在九個一般領域基準中表現優異,特別是在數學和編程方面。2.4B 模型在同類型模型中平均得分排名第一,展示了其在資源受限環境中的效率。同時,7.8B 和 32B 模型也取得了競爭力的得分,顯示出 EXAONE 3.5 在處理各種任務中的多樣性。
對負責任 AI 開發的承諾:LG AI 研究所在 EXAONE 3.5 的開發中優先考慮倫理考量和透明度。AI 倫理影響評估識別並解決了不平等、有害內容和誤用等潛在風險。這些模型在過濾仇恨言論和非法內容方面表現出色,儘管 2.4B 模型在解決地區和職業偏見方面仍需改進。透明的評估結果披露強調了 LG AI 研究所促進倫理 AI 開發的承諾,並鼓勵進一步研究負責任的 AI。
實際應用和商業合作:EXAONE 3.5 正在通過與 Polaris Office 和 Hancom 等公司的合作,融入現實世界應用中。這些合作旨在將 EXAONE 3.5 整合到軟體解決方案中,提高企業和公共部門的效率和生產力。與 Hancom 的概念驗證 (PoC) 項目突顯了 AI 驅動創新改變政府和公共機構工作流程的潛力,展示了該模型的實際商業價值。
結論:開源 AI 的新標準
總結來說,LG AI 研究所通過發布 EXAONE 3.5 設定了一個新的基準,這是一個包含三個模型系列的開源大型語言模型。EXAONE 3.5 結合了先進的指令跟隨能力和無與倫比的長上下文理解,旨在滿足研究人員、企業和行業的多樣需求。其多樣化的模型系列,2.4B、7.8B 和 32B,為資源受限環境和高性能應用提供了量身定制的解決方案。這些開源的三模型系列可以在 Hugging Face 上獲得。用戶可以通過關注 LG AI 研究所的 LinkedIn 頁面和 LG AI 研究所網站,獲取最新的更新、見解和參與其最新進展的機會。
來源
感謝 LG AI 研究團隊為這篇文章提供的思想領導/資源。LG AI 研究團隊在這篇內容/文章中支持了我們。
新聞來源
本文由 AI 台灣 使用 AI 編撰,內容僅供參考,請自行進行事實查核。加入 AI TAIWAN Google News,隨時掌握最新 AI 資訊!








{kind=link}